Python 具有丰富的解析库和简洁的语法,所以很适合写爬虫。这里的爬虫指的是爬取网页的“虫子”。简而言之,爬虫就是模拟浏览器访问网页,然后获取内容的程序。
爬虫工程师是个很重要的岗位。爬虫每天爬取数以亿计的网页,供搜索引擎使用。爬虫工程师们当然不是通过单击鼠标右键并另存的方式来爬取网页的,而会用爬虫“伪装”成真实用户,去请求各个网站,爬取网页信息。
本文选自《Python基础视频教程》一书,每一小节都给出了视频讲解,配合视频微课带你快速入门Python。

( 正 文 )
1、初识 HTTP :4行代码写一个爬虫
超文本传输协议(HyperText Transfer Protocol,HTTP)是网络中最常见的网络传输协议。常见网站的网址大都以 http 开头或者以 https 开头,https 在 http 基础上做了一层加密的协议。
通常情况下,在浏览器里给服务器发送 http 或 https 请求,服务器拿到请求后会向浏览器返回相应的结果(response),浏览器解析、润色后呈现给用户。
写爬虫没有那么难,下面用 4 行代码写一个爬虫。在 first_spider.py 文件中写入以下代码:
1from urllib import request
2page = request.urlopen('http://www.yuqiaochuang.com/')
3ret = page.read()
4print(ret)
python first_spider.py 运行后,会看到屏幕上打印出了页面的源代码,这短短 4行就是一个爬虫。
从本质上来说,这和打开浏览器、输入网址去访问没有什么区别,只不过后者是借助浏览器获取页面内容,而爬虫则是用原生的 HTTP 获取内容。屏幕上打印的源代码和在 Chrome 浏览器中单击鼠标右键,然后在弹出的快捷菜单中单击“查看网页源代码”是一样的。
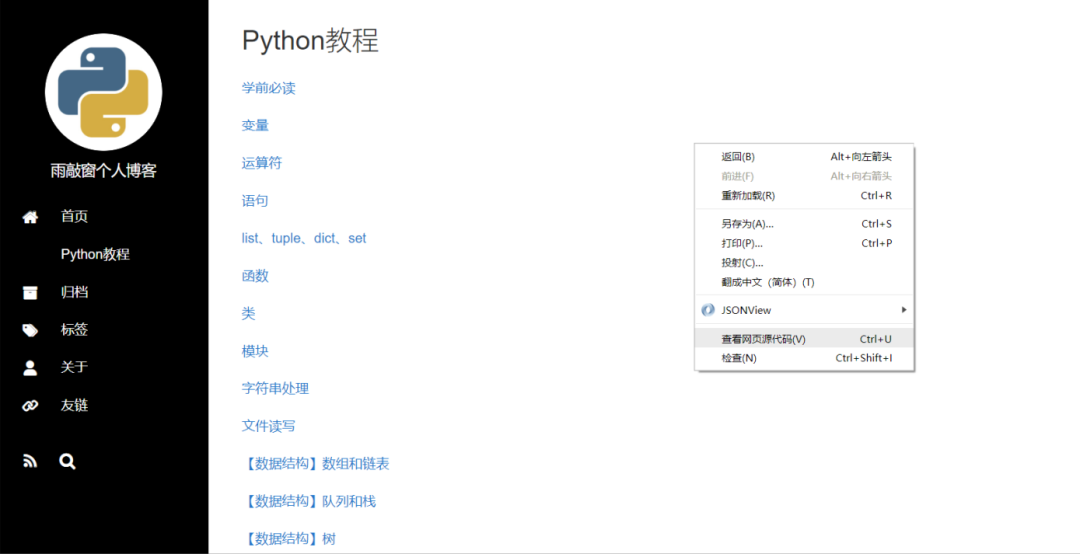
在此可以看到,网页的源代码是由很多标签组成的。

尖括号包围的就是一个标签,如<head>、<body>和<div>。标签内可以有属性,例如<html lang="zh-CN">,有一个值为"zh-CN"的 lang 属性,表示语言是中文。标签通常是成对出现的,例如,<title>Python 教程 - 雨敲窗个人博客</title>。“Python 教程 - 雨敲窗个人博客”被<title>和</title>包括起来,包括起来的部分被称为标签的内容。
2、正则表达式
前面用 4 行代码写了一个爬虫,运行成功后可以看到爬取的内容。不过,这却是一个大块的内容,如果想提取其中的某些字段该怎么办?
常用的做法就是用正则表达式(Regular Expression)提取。
对初学编程的人来说,很难理解正则表达式是“何方神圣”。其实大家可以把正则表达式当作一个提取器来看,通过制定一些规则,从字符串中提取出想要的内容。
下面先看看正则表达式的几个简单用法。在regular_expression.py 文件中写入以下代码:
1import re # 正则表达式的包
2
3m = re.findall("abc", "aaaaabcccabcc")
4print(m)
5m = re.findall("\d", "abc1ab2c")
6print(m)
7m = re.findall("\d\d\d\d", "123abc1234abc")
8print(m)
9m = re.findall(r"<div>(.*)</div>", "<div>hello</div>")
10print(m)
11m = re.findall(r"<div>(.*)</div>", "<div>hello</div><div>world</div>")
12print(m)
13m = re.findall(r"<div>(.*?)</div>", "<div>hello</div><div>world</div>")
14print(m)
python regular_expression.py 的运行结果如下:
1['abc', 'abc']
2['1', '2']
3['1234']
4['hello']
5['hello</div><div>world']
6['hello', 'world']
首先,需要“import re”,以引用正则表达式模块,这样才能使用正则表达式库中的方法。
之后,上述代码中的 m = re.findall("abc", "aaaaabcccabcc") 从"aaaaabcccabcc"中提取出"abc",返回的 m 是一个列表,里面有两个'abc'。
m = re.findall("\d", "abc1ab2c") 从"abc1ab2c"中提取出单个数字,"\d"表示提取的目标字符是数字,返回的结果是['1', '2'] 。
m = re.findall("\d\d\d\d", "123abc1234abc")提取 4 个连续的数字,返回的结果是['1234']。
m = re.findall(r"<div>(.*)</div>", "<div>hello</div>")从"<div>hello</div>"中提取出<div>和</div>中间的内容,括号括起来就表示提取括号中的内容,“.”表示可以匹配任何字符,“*”表示可以匹配任意多个字符,返回的结果是['hello']。
m = re.findall(r"<div>(.*)</div>", "<div>hello</div><div>world</div>")从"<div> hello</div><div>world</div>" 中 提 取 div 中 的 内 容 , 返 回 的 结 果 是 ['hello</div> <div>world']。与上一行的提取规则相同,为什么没有单独提取出 hello 和 world 呢?因为正则表达式默认用的是贪婪匹配,所谓贪婪匹配就是能匹配多长就匹配多长。"<div>hello</div><div>world</div>"就从头匹配到了末尾,提取出来一个大长串。
m = re.findall(r"<div>(.*?)</div>", "<div>hello</div><div>world</div>") 在括号中加入一个“?”就表示以非贪婪匹配去提取,即能匹配多短就匹配多短,所以提取出来的结果是['hello', 'world']。
结合前面的几个例子,可以总结出正则表达式中最常用的 findall 方法的用法。第一个参数是定义的提取语法,第二个参数是原始字符串。返回的是一个列表,列表里是符合提取规则的字符串。
关于正则表达式更详细的语法,大家可以借助搜索引擎,搜索“菜鸟教程正则表达式”。
3、爬取静态页面的网站
还 记 得 前 面 写 的 那 个 只 有 4 行 代 码 的 爬 虫 吗 ?它 爬 取 了 “ http://www. yuqiaochuang.com”整个页面的内容。在学过正则表达式之后,就可以提取想要的内容。
还是以爬取这个博客为例,提取这个博客上文章列表的标题。
在爬取一个网站前,通常要先分析一下这个网站是否是静态页面。静态页面是指,网站的源代码里包含所有可见的内容,也就是所见即所得。常用的做法是,在浏览器中单击鼠标右键,然后在弹出的快捷菜单中选择“显示网页源代码”,推荐使用 Chrome 浏览器。
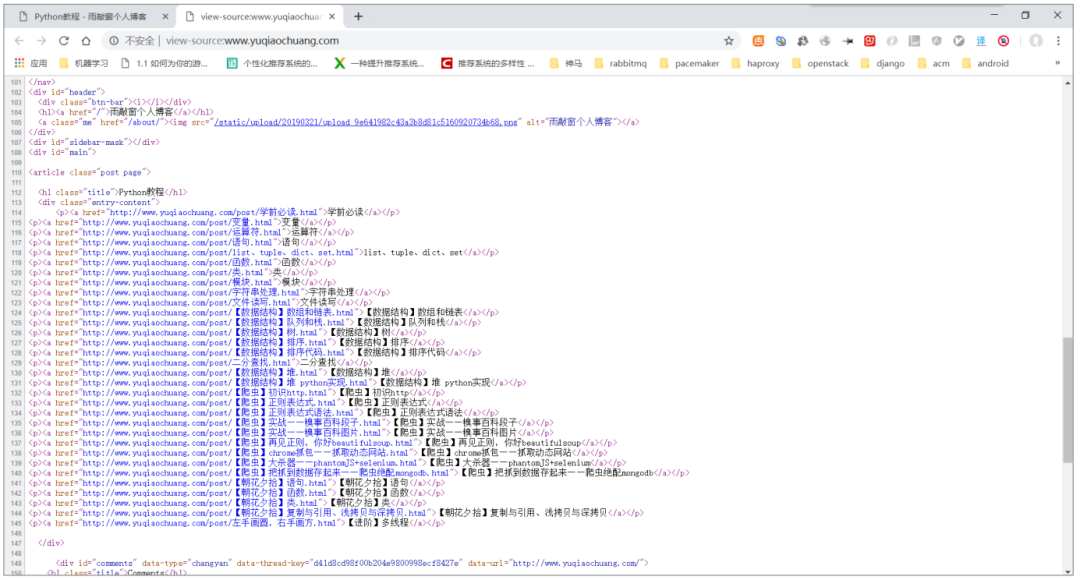
类似上图中的代码,就是网页的源代码,这里能够看到该博客中文章的标题和网址。
接下来使用正则表达式提取各标题。前面那个只有 4 行代码的爬虫用的是标准库里的urllib 库。推荐使用 requests 库,其具有更强大、更易用的功能。使用 pip 安装,在 PowerShell 命令行窗口中输入以下命令:
1pip install requests
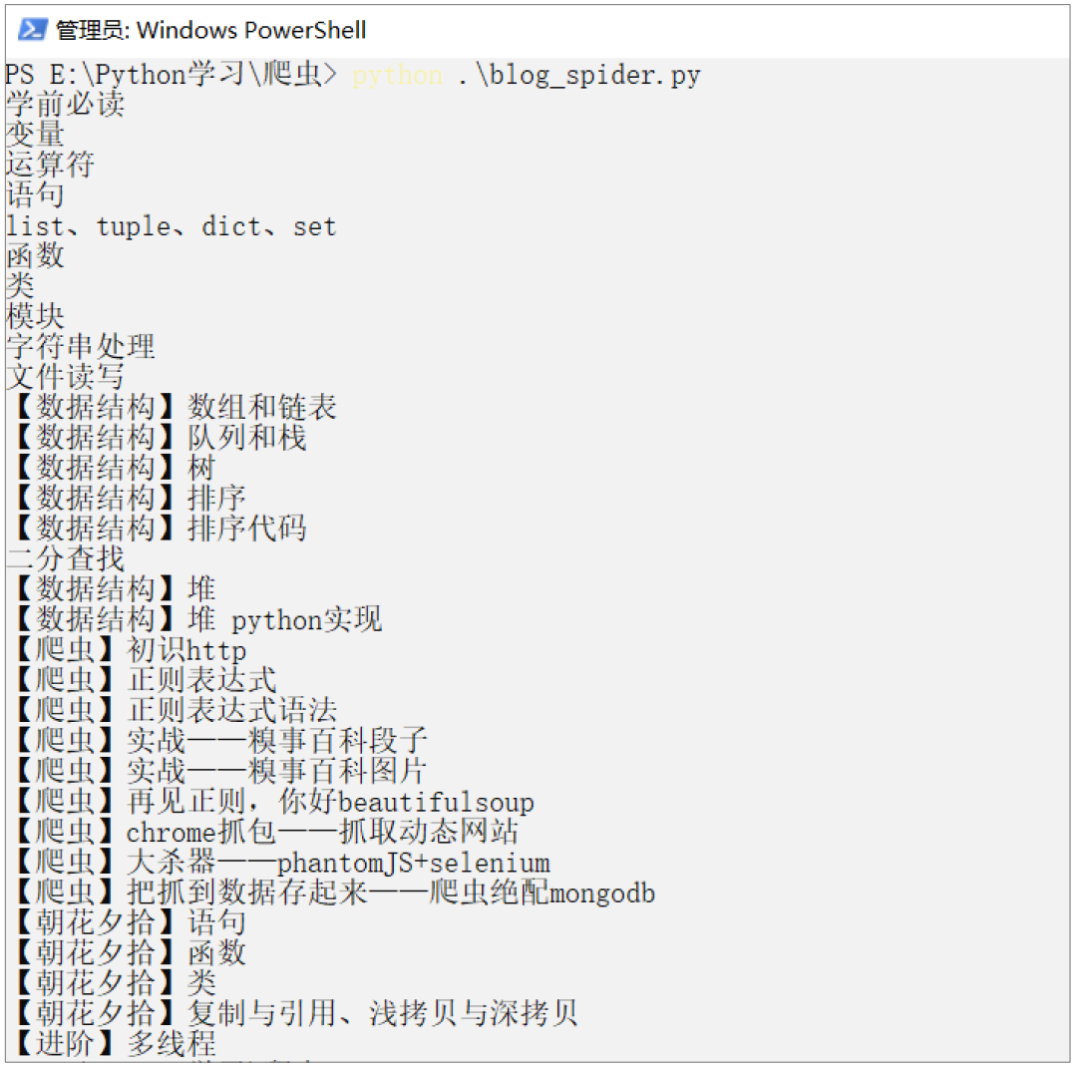
上述代码的前两行先将要使用的库“import”进来,然后调用 requests 库中的 get方法获取页面(page)。之后使用 re.findall 方法提取所有的标题,page.text 即页面的源代码内容。将页面中以“<p><a.*>”开头、“</a></p>”结尾的标题提取出来。
若欲了解更多与 requests 库相关的资料,可以借助搜索引擎,搜索“python requests”查看具体用法。
4、beautifulsoup4
beautifulsoup4 也是一个 Python 的第三方库,提供解析网页的功能。其有些类似于正则表达式,但是比正则表达式的语法更加优雅和便利。
在 PowerShell 命令行窗口中输入以下命令安装 beautifulsoup4:
1pip install beautifulsoup4
还是以“
http://www.yuqiaochuang.com”的网页源代码为例,提取这些文章的标题和链接。在 blog_spider_use_bs4.py 文件中写入以下代码:
1from bs4 import BeautifulSoup
2import requests
3page = requests.get('http://www.yuqiaochuang.com/')
4soup = BeautifulSoup(page.text, features="html.parser")
5all_title = soup.find("div", "entry-content").find_all("a")
6for title in all_title:
7 print(title["href"], title.string)
“from bs4 import BeautifulSoup ”将 BeautifulSoup 引 进 程 序 。
“ soup = BeautifulSoup(page.text, features="html.parser")”声明了一个解析结构 soup。这里解析的是爬取的网页源代码 page.text;features 指定了“html.parser”这个默认的解析器。
在此可以看到,想爬取的标题都在 class 是“entry-content”的 div 块中。“soup.find("div", "entry-content")”用于提取 class 是“entry-content”的 div 块。紧接着调用 find_all,爬取所有标题的标签。find_all 方法返回的是一个列表,这个列表中的元素是符合查找条件的标签。
然后写一个循环,把标题的标签打印下来。通过调用 title["href"]可以获取标签中属性的值—链接。title.string 则是获取标签中的内容。

5、爬取图片
如果网站中仅有枯燥的文字,则很难吸引用户持续观看,所以,好的网站都是图文并茂的。如果想将图片也爬取下来,该怎么办呢?爬虫当然也可以爬取图片,就像在用浏览器访问网站时,可以在图片上单击鼠标右键,然后在弹出的快捷菜单中选择“另存为”选项去下载图片一样。
利用 requests 库也可以抓取图片。还是以爬取“
http://www.yuqiaochuang.com”为例,这次爬取网站左上角的图片。在左上角的图片上面单击鼠标右键,接着在弹出的快捷菜单中选择“检查”。
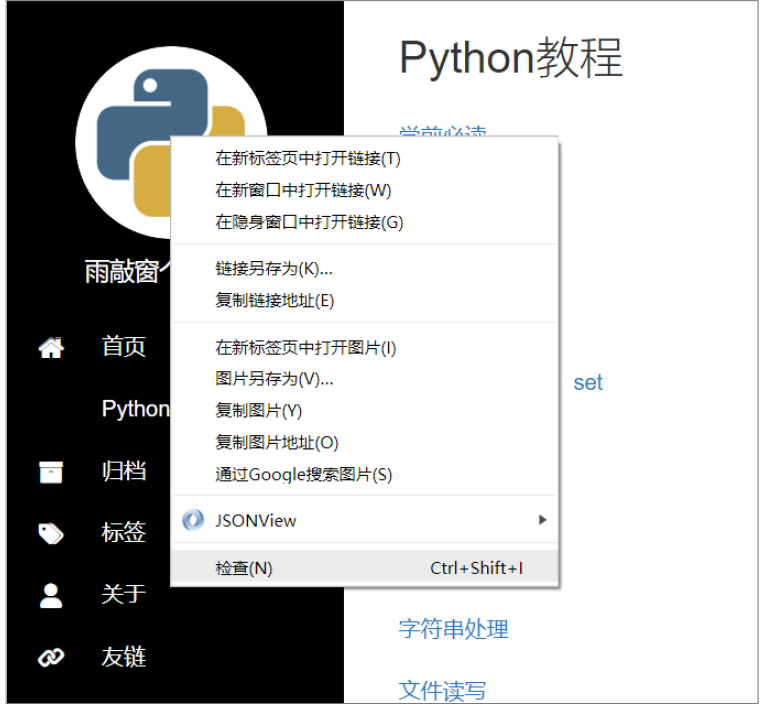
在此可以看到,浏览器下方区域出现了一个工具栏,里面突出显示的部分就是图片地址的网页源代码。
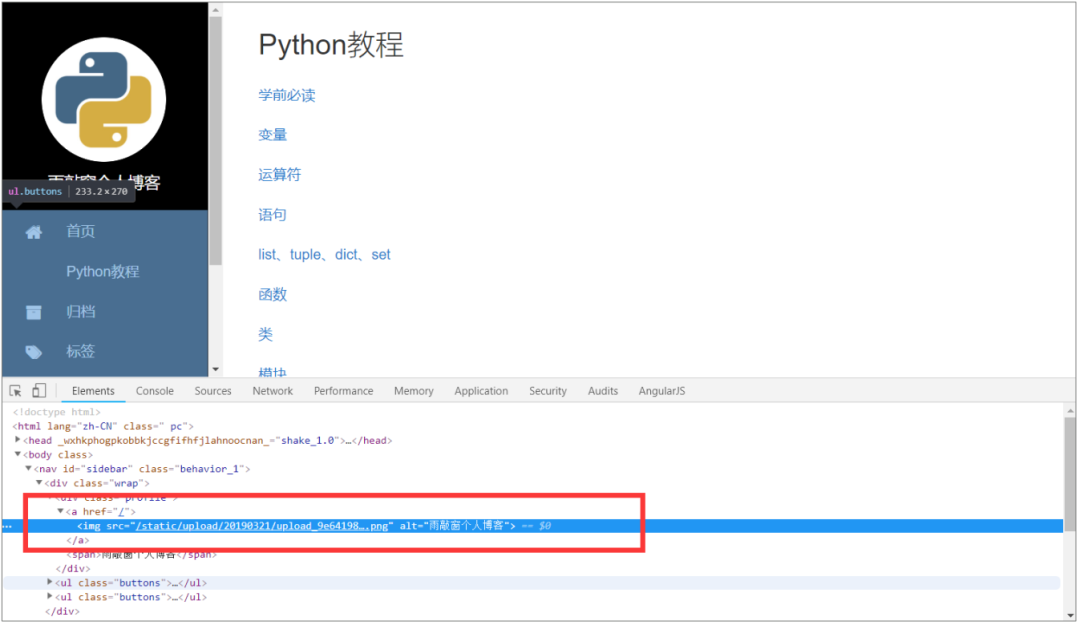
在此可以看到,图片是以“img”标签开头的。这个“img”标签在 class 是“profile”的 div 中,因此可以使用 requests+beautifulsoup4 提取图片的地址。
在 image_spider.py文件中写入以下代码:
1from bs4 import BeautifulSoup
2import requests
3
4page = requests.get('http://www.yuqiaochuang.com/')
5soup = BeautifulSoup(page.text, features="html.parser")
6img = soup.find("div", "profile").find("img")
7print(img["src"])
python image_spider.py 的运行结果如图下。

soup.find("div", "profile").find("img") 直接提取了 img 标签,然后打印 img 标签中的 src 字段,在此可以看到图片地址被提取了出来。但是,你有没有发现这个链接地址似乎少了一些前缀?
没错,少了"
http://www.yuqiaochuang.com"。有些网站的图片会省略前缀,在爬取时补上即可。接下来正式爬取图片,在 image_spider.py 文件中写入以下代码:
1from bs4 import BeautifulSoup
2import requests
3
4page = requests.get('http://www.yuqiaochuang.com/')
5soup = BeautifulSoup(page.text, features="html.parser")
6img = soup.find("div", "profile").find("img")
7
8image_url = "http://www.yuqiaochuang.com" + img["src"]
9img_data = requests.get(image_url)
10img_file = "image.png"
11
12f = open(img_file, 'wb')
13f.write(img_data.content)
14f.close()
python image_spider.py 运行后,可以看到当前文件夹下多了一个“image.png”图片文件。
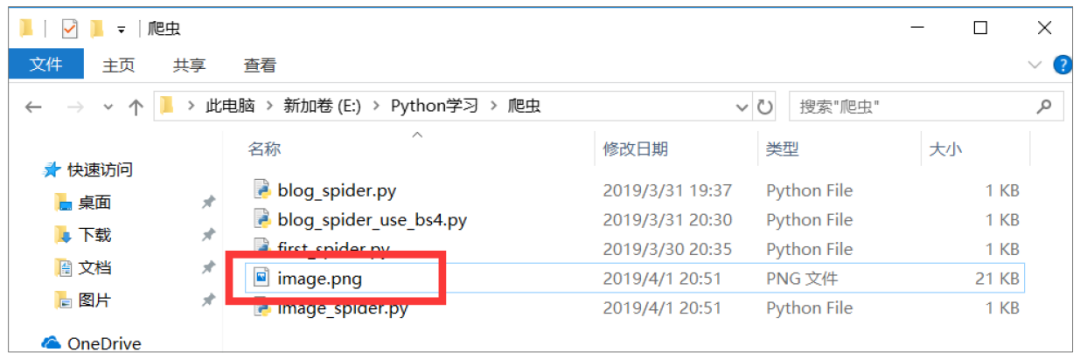
在获取图片地址后,调用 requests 的 get 方法,获取图片的请求数据,然后调用写文件的方法,将图片数据写入到文件中。
前面爬取文字时,调用的是 text 字段,为什么这里变成了 content 字段呢?
这是因为 content 是最原始的数据,二进制的数据流;而 text 则是经过编码的数据。在写文件时,参数也不是'w',而是'wb'。'wb'的意思是,写入的数据是二进制数据流,而不是经过编码的数据。爬取图片和爬取文字的本质,都是根据网页链接发送请求,然后获取内容,只不过图片需要用二进制的形式保存到本地文件中。
—— 完 ——
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至举报,一经查实,本站将立刻删除。

投诉举报

平台公司是什么公司(平台公司和国企的区别)

创业融资需求有什么特点(创业风险融资的特点
小灵通创始人(当年叱咤风云的小灵通之父现状
新加坡注册公司(新加坡公司注册条件流程攻略

有营业执照可以申请创业基金吗(青年创业促进

大学生创业计划书封面图片(创业项目策划书模
